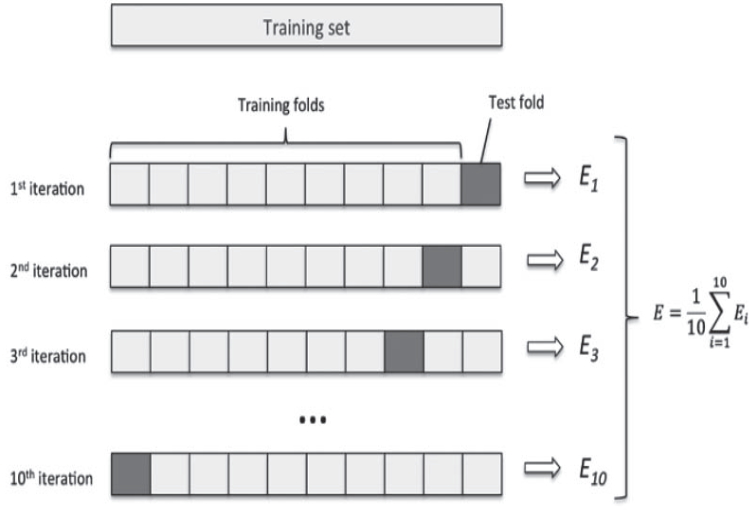
Time-Series 데이터의 경우 일반적인 머신러닝 문제에 사용되는 교차 검증 방법을 사용해서는 안 됩니다.여러 가지 방법이 있겠지만 Expanding Window Validation(=Walking Forward) 방식을 만들어 보겠습니다. (reference: https://medium.com/eatpredlove/time-series-cross-validation-a-walk-forward-approach-in-python-8534dd1db51a)

아래 Time-Series 데이터가 있다.여기에 총 16개의 Feature가 존재하며 2015년 9월부터 2020년 6월까지의 row 데이터가 있다.
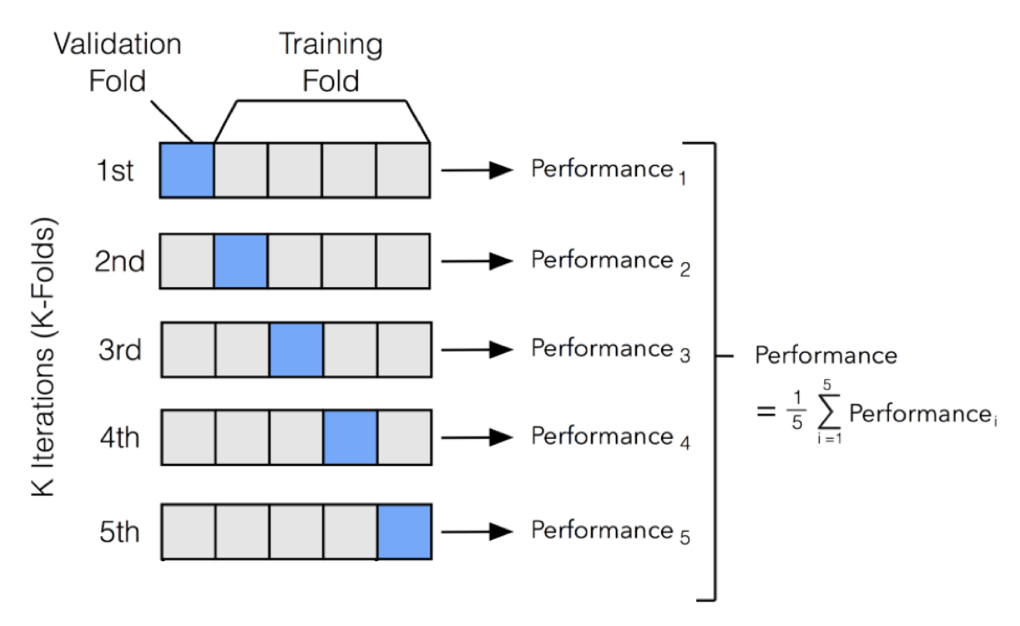
ML 모델을 적용해 데이터를 학습시켜야 하는데 일반적인 Cross-Validation 방식을 사용하면 Time-Series 특성을 무시한 채 random에게 학습시키게 된다.이를 방지하기 위해 여러 validation 방식이 존재하는데, 내가 현재 가지고 있는 데이터의 경우 row 개수가 작으므로 Expanding Window Validation 방식을 적용해 볼 예정이다.만약 데이터 규모가 훨씬 클 경우 Fixed window Validation 방식을 적용해도 된다.
인기글
![[시험후기] 데이터 분석 시험 합격 리뷰 - 1탄](https://dojang.io/pluginfile.php/17269/block_html/content/%ED%8C%8C%EC%9D%B4%EC%8D%AC%EC%BD%94%EB%94%A9%EB%8F%84%EC%9E%A5%EB%A6%AC%EB%89%B4%EC%96%BC_%EC%95%9E%EB%A9%B4.jpg "[시험후기] 데이터 분석 시험 합격 리뷰 - 1탄")


자생윈드림관악단-색소폰")
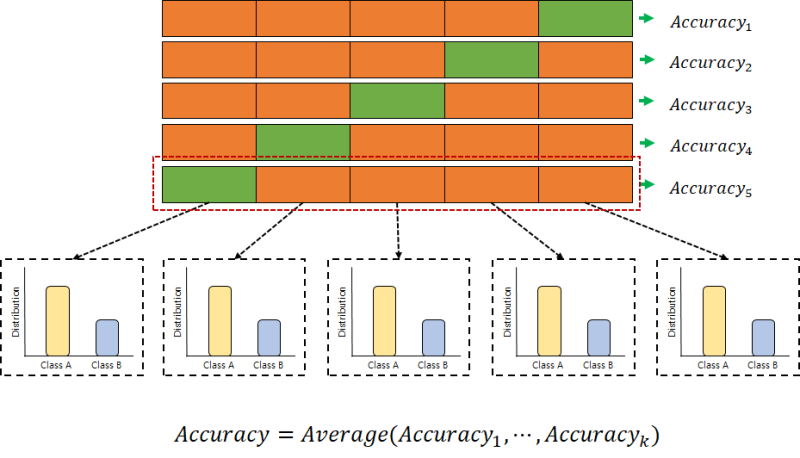
from sklearn.model_slot import Time SeriesPandas pdef time_series_session(데이터, 번호) : timeSeries_object(n_splits=number) timeSplit(train_index의 경우 타임시리즈 스플릿=[], 시계열 객체의 경우 valid_index intime_session.hypandes([traindes, valid_index])를 반환합니다.DataFrame(time_series_index, columns=[“train_index”, “valid_index”]])

from sklearn.model_slot import Time SeriesPandas pdef time_series_session(데이터, 번호) : timeSeries_object(n_splits=number) timeSplit(train_index의 경우 타임시리즈 스플릿=[], 시계열 객체의 경우 valid_index intime_session.hypandes([traindes, valid_index])를 반환합니다.DataFrame(time_series_index, columns=[“train_index”, “valid_index”]])
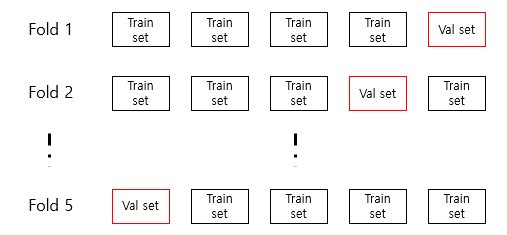
내일은 Walk Forward Cross Validation을 실제로 해보고 Hyperparameter tunning까지 해볼 계획입니다.